Questo articolo appare in lingua inglese anche sul blog di SUSE.
La domanda di cloud storage è costantemente aumentata nel corso degli ultimi anni e le organizzazioni richiedono che i loro dati siano sempre più accessibili per le loro applicazioni cloud native.
In un ambiente cloud native è importante offrire sistemi di storage che possano interagire con le applicazioni usando protocolli standard.
Simple storage service
 Simple Storage Service, o semplicemente: S3, è un protocollo sviluppato da Amazon e lanciato sul mercato statunitense nel 2006. S3 è un protocollo molto vasto che copre concetti come: buckets, objects, keys, versioning, ACLs and regions.
Simple Storage Service, o semplicemente: S3, è un protocollo sviluppato da Amazon e lanciato sul mercato statunitense nel 2006. S3 è un protocollo molto vasto che copre concetti come: buckets, objects, keys, versioning, ACLs and regions.
Per la lettura di questo articolo, tutto ciò di cui abbiamo bisogno di sapere è che il set API di S3 può essere invocato via REST. Possiamo semplicemente immagazzinare i nostri oggetti in contenitori chiamati: buckets. Per ulteriori informazioni sul protocollo, ci sono molte altre risorse disponibili in rete.
K3s e Rancher
 In questo articolo esploriamo l’uso di K3s e di Rancher come basi per sperimentare con un gateway S3.
In questo articolo esploriamo l’uso di K3s e di Rancher come basi per sperimentare con un gateway S3.
K3s è un Kubernetes leggero che può girare fluido su componenti Edge con dispongono di risorse limitate.
Rancher invece, è un manager grafico che semplifica alcune delle complessità di un cluster Kubernetes.
Con Rancher, possiamo gestire un cluster in maniera relativamente semplice indipendentemente dalla versione di Kubernetes impiegata.
dalla versione di Kubernetes impiegata.
longhorn
 Un cluster Kubernetes e un manager grafico da soli non sono sufficienti quando parliamo di storage in cloud. Potremmo impiegare direttamente le risorse offerte dalle API di Kubernetes e lavorare, per esempio, con i tipi base di Persistent Volume.
Un cluster Kubernetes e un manager grafico da soli non sono sufficienti quando parliamo di storage in cloud. Potremmo impiegare direttamente le risorse offerte dalle API di Kubernetes e lavorare, per esempio, con i tipi base di Persistent Volume.
Tuttavia, poichè esistono implementazioni avanzate e mature, non ci sono motivi particolari per non impiegarle.
In particolare, ci piacerebbe che un Persistent Volume possa avere la capacità di replicare i dati su nodi differenti.
Le caratteristiche di sicurezza relative alla gestione della ridondanza sono cruciali e garantiscono che il fallimento di un’unità di archiviazione fisica non comprometta in alcun modo l’integrità e la fruibilità dei dati dell’utente.
Longhorn è il sistema giusto per questo tipo di necessità. La porzione di archiviazione gestita da Longhorn è mantenuta replicata tra i nodi e i Pod accedono ai loro dati in modo naturale via Persistent Volume.
s3gw
![]() Le applicazioni interne al cluster possono consumare i Persistent Volume resi disponibili da Longhorn mediante le classiche API di Kubernetes.
Le applicazioni interne al cluster possono consumare i Persistent Volume resi disponibili da Longhorn mediante le classiche API di Kubernetes.
Tuttavia, se la necessità è quella di fornire un accesso ai volumi a client esterni ecco che si rende necessario l’impiego di un gateway S3.
Per questo ruolo possiamo utilizzare un gateway S3 opensource: s3gw.
s3gw è sviluppato sulle fondamenta del gateway S3 ufficiale utilizzato da Ceph: radosgw.
Anche se s3gw è attualmente in una fase di sviluppo pressochè iniziale, può essere utilizzato per testare le funzionalità S3.
cuciniamo gli ingredienti
Ora che abbiamo identificato tutti i componenti, siamo pronti per costruire il nostro ambiente di test.
In questo tutorial, installeremo K3s su un sistema OpenSUSE Linux.
Per semplicità, poichè Kubernetes ha bisogno di certe risorse di rete disponibili, andremo a disabilitare completamente il firewall di sistema.
Poichè questo può non essere desiderabile, qui ci sono i dettagli per chi volesse una configurazione precisa del firewall.
Stop firewall
Da una shell, eseguiamo il seguente comando:
$ sudo systemctl stop firewalld.service
installazione di k3s
Da una shell, eseguiamo il seguente comando:
$ curl -sfL https://get.k3s.io | INSTALL_K3S_VERSION=v1.23.9+k3s1 sh -
Dopo che l’installazione è terminata, possiamo controllare lo stato del cluster con:
$ sudo kubectl get nodes
Se è tutto ok, dovremmo vedere qualcosa di simile:
NAME STATUS ROLES AGE VERSION suse Ready control-plane,master 56s v1.23.8+k3s1
Se preferiamo utilizzare K3s con un utente non-root, senza utizzare sudo, possiamo eseguire il seguente comando:
$ sudo cp /etc/rancher/k3s/k3s.yaml ~/.kube/config && chown $USER ~/.kube/config && chmod 600 ~/.kube/config && export KUBECONFIG=~/.kube/config
Una volta eseguito, l’utente non-root sarà in grado di operare normalmente sul cluster.
installiamo helm
 Installeremo Rancher utilizzando un Helm chart, quindi dobbiamo installare Helm sul nostro sistema:
Installeremo Rancher utilizzando un Helm chart, quindi dobbiamo installare Helm sul nostro sistema:
$ sudo zypper install helm
effettuiamo il deploy di rancher
Cominciamo con l’aggiungere gli ultimi repository di Rancher ad Helm:
$ helm repo add rancher-latest https://releases.rancher.com/server-charts/latest
Dopodiché, definiamo un namespace in Kubernetes dove andremo ad installare Rancher:
$ kubectl create namespace cattle-system
La documentazione ufficiale vuole che questo namespace sia chiamato: cattle-system.
Poiché il servizio di Rancher è pensato per essere sicuro per default, questo richiede una configurazione SSL/TLS. Per questo motivo, occorre fare il deploy di alcune risorse aggiuntive:
$ kubectl apply -f https://github.com/cert-manager/cert-manager/releases/download/v1.7.1/cert-manager.crds.yaml $ helm repo add jetstack https://charts.jetstack.io $ helm install cert-manager jetstack/cert-manager \ --namespace cert-manager \ --create-namespace \ --version v1.7.1
Controlliamo che il cert-manager sia stato correttamente installato e che i pod relativi siano in esecuzione:
$ kubectl get pods --namespace cert-manager
NAME READY STATUS RESTARTS AGE cert-manager-5c6866597-zw7kh 1/1 Running 0 2m cert-manager-cainjector-577f6d9fd7-tr77l 1/1 Running 0 2m cert-manager-webhook-787858fcdb-nlzsq 1/1 Running 0 2m
Ora, dobbiamo definire un hostname in /etc/hosts che punti ad un indirizzo ip associato ad una delle interfacce fisiche dell’host.
Ad esempio:
10.0.0.2 rancher.local
Fatto ciò, possiamo finalmente lanciare l’installazione di Rancher:
helm install rancher rancher-latest/rancher \ --namespace cattle-system \ --set hostname=rancher.local \ --set bootstrapPassword=admin
Una volta che i pod di Rancher saranno pronti, possiamo navigare con il nostro browser alla pagina: https://rancher.local e completare il setup iniziale:

Una volta completato questo passo, possiamo cominciare ad esplorare il cluster con il manager grafico:
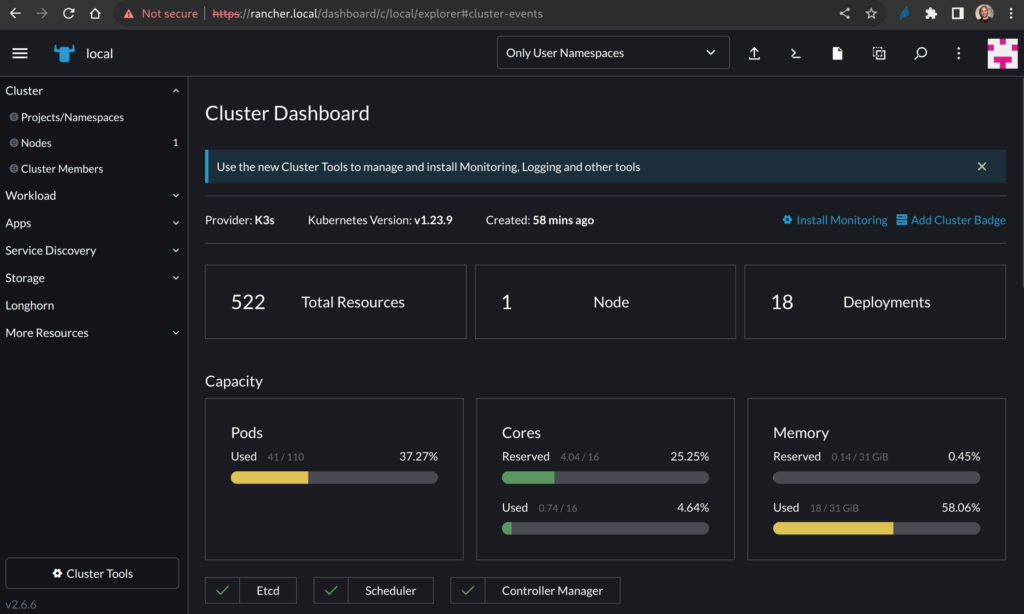
A seconda di cosa abbiamo installato nel cluster, potremmo vedere più o meno risorse impiegate.
effettuiamo il deploy di LONGHORN
Possiamo effettuare il deploy di Longhorn utilizzando la schermata relativa ai Charts sotto la sezione Apps del menù di sinistra:

L’installazione è molto semplice e per i nostri scopi non abbiamo bisogno di modificare alcun valore di default del chart.
Alla fine, se tutto è andato bene dovremmo poter vedere la console di Rancher mostrare qualcosa di simile:

Al termine dell’installazione, possiamo cliccare sulla voce Longhorn nel menù di sinistra per poter essere rediretti alla dashboard di Longhorn:

Una nuova installazione di Longhorn mostra che ancora nessuna applicazione sta utilizzando un persistent volume.
effettuiamo il deploy di s3gw
Siamo finalmente pronti per installare l’ultimo ingrediente del nostro sistema: s3gw, il gateway S3.
Poichè Rancher non viene distribuito (ancora) con il chart di s3gw, occorre importarlo manualmente dalla sezione Repositories:

Possiamo scegliere il nome che preferiamo, ad esempio: s3gw.
Nel campo Target andiamo a scegliere: Git repository.
Nel campo Git Repo URL inseriamo:
https://github.com/aquarist-labs/s3gw-charts
Nel campo Branch possiamo inserire l’ultima versione disponibile, che al momento della scrittura di questo post è:
v0.5.0
Una volta cliccato su Create, nella sezione Apps troveremo anche il chart di s3gw:
Procediamo quindi con l’installazione; possiamo scegliere il namespace e il nome per s3gw.
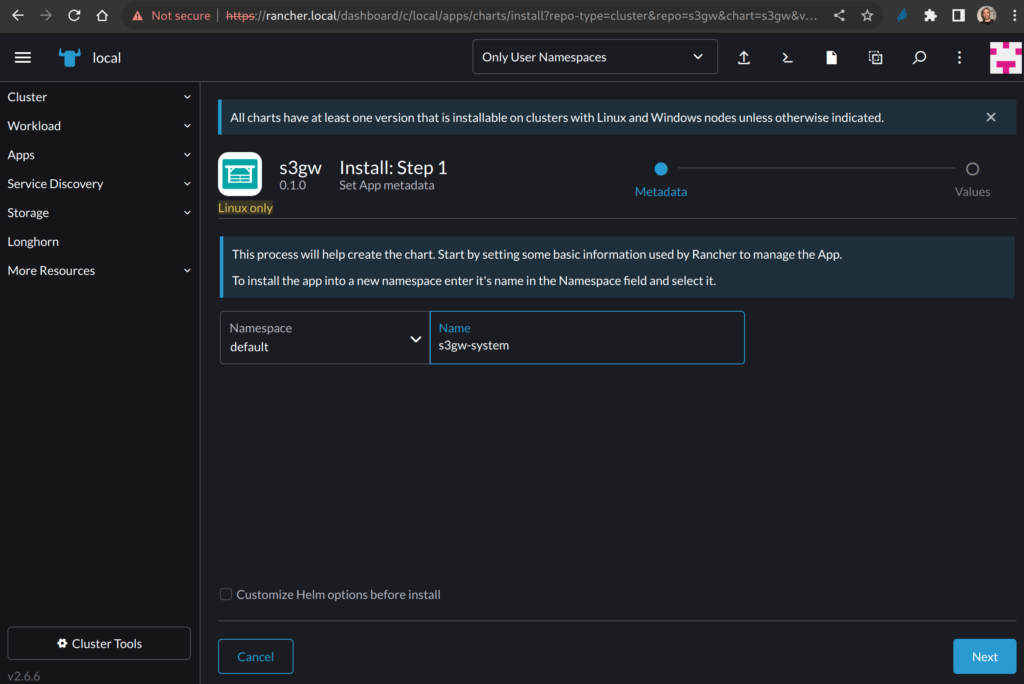
Non abbiamo bisogno di personalizzare il chart, quindi possiamo lasciare la checkbox in basso così com’è.
Una volta completata l’installazione, dovremmo vedere qualcosa di simile:
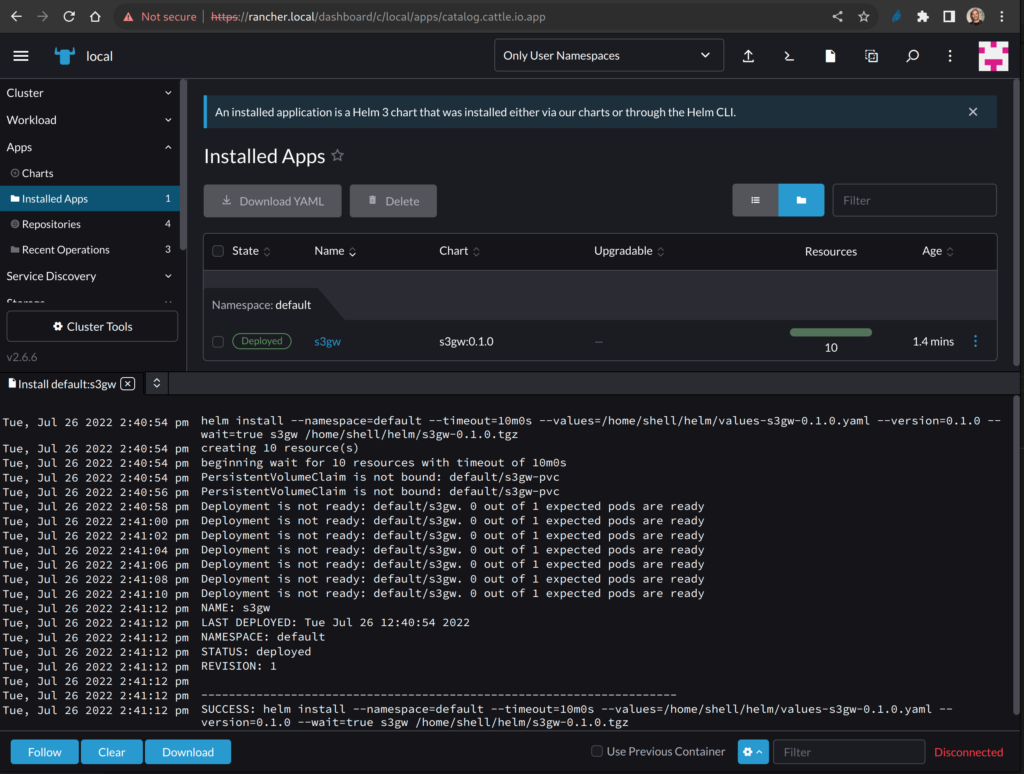
Se andiamo sulla dashboard di Longhorn, possiamo verificare che adesso un’applicazione sta utilizzando un persistent volume gestito da Longhorn:

testiamo il gateway
Per default, il chart di s3gw configura una risorsa ingress che punta al pod del gateway S3 con FQDN: s3gw.local .
Per questo motivo occorre definire in /etc/hosts una riga che risolva s3gw.local, ad esempio:
10.0.0.2 s3gw.local
Per testare il gateway S3 possiamo impiegare s3cmd, un client S3 a riga di comando molto popolare.
Possiamo installarlo con uno dei metodi descritti qui.
Una volta installato, possiamo prendere la configurazione di s3cmd a questo indirizzo e impiegarla per testare s3gw.
creiamo un bucket
$ s3cmd -c s3cmd.cfg mb s3://foo
effettuiamo l’upload di alcuni oggetti
Creiamo un file da 1 megabyte e effettuiamo l’upload:
$ dd if=/dev/random bs=1k count=1k of=obj.1mb.bin $ s3cmd -c s3cmd.cfg put obj.1mb.bin s3://foo
Creiamo un file da 10 megabyte e effettuiamo l’upload:
$ dd if=/dev/random bs=1k count=10k of=obj.10mb.bin $ s3cmd -c s3cmd.cfg put obj.10mb.bin s3://foo
verifichiamo lo stato del bucket
$ s3cmd -c s3cmd.cfg ls s3://foo 2022-07-26 15:03 10485760 s3://foo/obj.10mb.bin 2022-07-26 15:01 1048576 s3://foo/obj.1mb.bin
cancelliamo un oggetto
$ s3cmd -c s3cmd.cfg rm s3://foo/obj.10mb.bin
per concludere
In questo tutorial, abbiamo visto come effettuare l’installazione di un cluster K3s e di come sia possibile installare Rancher per avere un manager grafico per Kubernetes.
Abbiamo poi installato Longhorn per arricchire il sistema con un gestore avanzato di volumi persistenti.
Infine, abbiamo installato un gatway S3 per esporre i dati contenuti da questi volumi a clienti esterni.
per Saperne di più e per contribuire al progetto s3gw
Contattaci su GitHub!