
INTRODUZIONE
In questo articolo andremo a vedere come è possibile realizzare applicazioni altamente disponibili e in grado di scalare automaticamente in base al carico utilizzando la soluzione IaaS di Google. Spesso si tende a pensare che questi requisiti si possono ottenere solo con soluzioni PaaS e con Kubernetes. Non voglio sminuire Kubernetes, è sicuramente la piattaforma migliore quando si ha bisogno di HA e scalabilità ma non tutti i software sono stati progettati con i principi del cloud native: parliamo di software legacy con un architettura monolitica e non a microservizi e applicativi progettati per non essere distribuiti come container. E anche se fato lo sforzo di “dockerizzare” il vostro monolite, deployarlo su Kubernetes non ha proprio senso; vi prendete in carico tutto il costo di avere un cluster senza trarne i suoi reali benefici. Per questa tipologia di software è consigliato appoggiarsi a soluzioni di tipo IaaS ! Andiamo a vedere cosa ci mette a disposizione Google su IaaS per realizzare applicazioni scalabili e con HA ( alta affidabilità).
gestire il picco del traffico su iaas
Il servizio IaaS di Google è Compute Engine: il servizio di gcp che permette di creare Virtual Machine (VM) disponibili nei data center di Google. E’ possibile creare Virtual Machine dimensionate con le risorse necessarie alle proprie esigenze: puoi scegliere il numero delle vCpu, RAM, tipologia di disco e capacità, GPU etc. Non è mai semplice prevedere il traffico della propria applicazione e stimare le risorse necessarie della propria Virtual Machine. A peggiorare la cosa è che spesso il traffico verso le nostre applicazioni non è costante; immaginate di dover realizzare un e-commerce: nel grosso dei periodi dell’anno una VM e2-standard-4 (4 vCPU, 16 GB memory) è sufficiente per gestire il vostro carico, ma ci sono periodi dell’anno in cui fate saldi e dove il vostro traffico aumenta drasticamente. Nei momenti di saldo abbiamo bisogno di bilanciare il carico con almeno due VM ma non vogliamo prenderci il costo di avere H24 2 VM running quando non ce n è bisogno e allo stesso tempo non vogliamo accendere/spegnere la seconda VM manualmente perché alle volte non è prevedibile l’aumento del carico. Non preoccupatevi … google ci viene in aiuto con i managed instance group ( abbrevierò da ora in poi con la sigla MIG). Andiamo a vedere di cosa sto parlando.
MANAGED INSTANCE GROUP (MIG)
I MIG sono gruppi “dinamici” di VM identiche. Le VM che fanno parte del gruppo vengono create a partire da un instance template: una specifica di una configurazione VM (tipo di macchina, immagine, zona etc). Ho definito i MIG come gruppi dinamici perché i gruppi possono ridimensionare automaticamente il numero di istanze in base al carico e bilanciare quest’ultimo distribuendo i carichi di lavoro tra le VM del gruppo. Se una VM del gruppo non è in salute (ad esempio non risponde o il load average è troppo alto), il managed instance group provvederà a riavviare la VM. Per bilanciare il carico tra le varie VM del gruppo è possibile utilizzare Cloud Load Balancing: il servizio managed per il load balancer che offre gcp il quale permette di fare da frontend per le richieste verso il nostro backend e bilanciare il carico delle richieste tra le VM del gruppo ( per farla semplice immagine che sia una sorta di apache o nginx gestito totalmente da google).
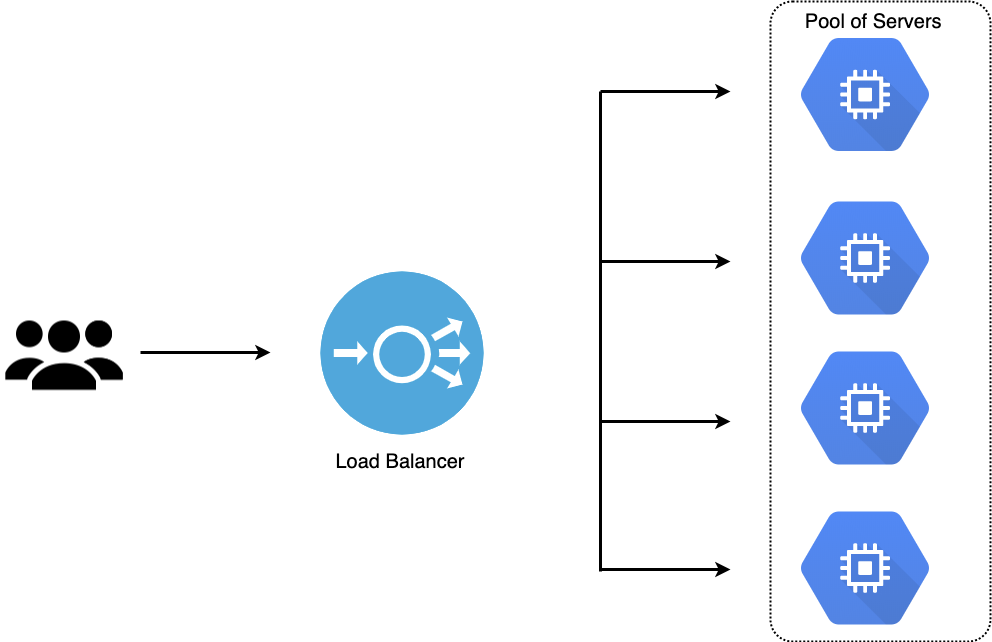
tutorial mig
In questo tutorial andremo a deployare un set dinamico di VM su cui girerà una semplicissima applicazione REST di hello world. Il codice sorgente di questa Spring Boot application lo trovate al seguente URL. Riassumo le caratteristiche di tale servizio:
- gira sulla porta 8080
- si aspetta una proprietà stringa da passare nella CLI al momento del lancio
- espone un HTTP endpoint che risponde a richieste GET al path /hello e che risponde con una stringa che riporta il messaggio hello by instance: {instance_id}
Il set di VM non sarà esposto direttamente su Internet; configureremo il servizio google di load balancing per fare da frontend verso i client e per bilanciare il carico tra le diverse VM running nel MIG sfruttando l autoscaler per aggiungere VM al gruppo quando il carico è troppo alto.
1- creazione instance template
La primissima cosa da realizzare per gestire un MIG è la creazione dell instance template: la specifica che consente di creare VM identiche da inserire nel MIG. Per installazioni particolarmente complesse una buona soluzione è quella di prepararsi una custom image contenente sistema operativo + pacchetti e software necessari per far girare la nostra applicazione. Il modo più veloce di creare un immagine è quello di crearla a partire da VM “campione”: una VM configurato con tutto il necessario per far girare la nostra applicazione.
1.A- creazione immagine
Andiamo quindi a creare una VM configurata con tutto il necessario che ci serve per il nostro tutorial:
- CentOS 7 come SO
- Java
- jar del nostro servizio REST salvato su disco

Una volta creata la VM, colleghiamoci via SSH e procediamo a installare il necessario:
sudo yum -y update sudo yum -y install java-1.8.0-openjdk sudo mkdir -p /app
e provvediamo a caricare il jar della nostra applicazione REST di esempio ( potete scaricarla da questo LINK) al path /app. A questo punto possiamo spegnere la VM e creare a partire di questa VM campione una custom image.

Grazie all’immagine creata, MIG sarà in grado di creare VM identiche alla nostra macchina campione ( stesso OS, pacchetti installati e dati).
1.b- creazione DI UNA REGOLA FIREWALL
Prima di creare l instance template abbiamo bisogno di creare una regola firewall da applicare all instance template. La nostra REST application girerà sulla porta 8080 delle nostre VM e non dovrà essere esposta direttamente su internet ma dovrà essere raggiungibile dal cloud load balancing di google. Google ci fornisce i CIDR che rappresentano il load balancing: 130.211.0.0/22, 35.191.0.0/16. Occorre quindi creare una regola firewall di tipo ingress che abiliti dalle sorgenti 130.211.0.0/22, 35.191.0.0/16 richieste sulla porta 8080 di tipo TCP.

1.C- creazione instance template
Procediamo quindi a creare un instance template a partire della nostra immagine

Nella nostra custom-image abbiamo caricato il nostro jar nella folder /app. Non basta quindi fare lo start della VM per avere il nostro servizio running; occorre anche lanciare il nostro servizio REST non appena la VM è running. GCP ci permette di specificare uno startup script dove includere i comandi da lanciare ogni volta che la VM viene avviata. Andiamo quindi a specificare nello startup script le seguenti istruzioni:
#! /bin/bash java -jar /app/rest-demo-0.0.1-SNAPSHOT.jar --hello.instanceId=$HOSTNAME > log
In breve stiamo andando a configurare il template per creare VM che all’avvio lancino il nostro servizio REST ($HOSTNAME è una env variable che viene valorizzata in automatico con il nome della VM).
Applichiamo infine nel menu networking la regola firewall precedentemente creata per abilitare le richieste al nostro servizio da parte del load balancing e completiamo la creazione del nostro instance template.
2- creazione managed instance group
A questo punto possiamo creare il set di VM utilizzando il template appena creato come entry point per creare automaticamente le VM del gruppo.

È possibile configurare un criterio di scalabilità automatica per attivare l’aggiunta o la rimozione di istanze basate sull’ utilizzo della CPU, metriche di monitoraggio, capacità di bilanciamento del carico, ecc. Procediamo quindi a configurare le direttive di autoscaling del gruppo.

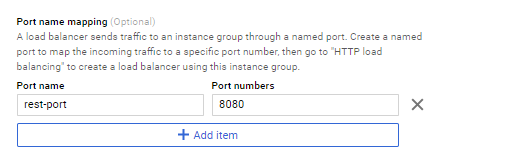
Abbiamo configurato il gruppo per avere almeno un istanza nel gruppo, e per autoscalare fino ad un massimo di 3 istanze sulla base del carico medio di tutte le vCPU del gruppo: se il valore medio è sopra il 60% l autoscaler aggiungerà una VM in modo da gestire il picco di traffico; l autoscaler continuerà a monitorare la metrica configurata per stoppare le VM se il carico è tornato a valori sotto la soglia. Per una descrizione dettagliata di come l autoscaler prende le decisione vi rimando alla seguente documentazione. Andiamo a definire la named-port del gruppo: possiamo definire degli alias a porte utilizzate dalle VM del gruppo in modo che il load balancer possa referenziare tali porte nelle regole di forwarding che vedremo dopo. Andiamo quindi a definire una named port con alias rest-port la quale punta alla porta 8080 che risponde al nostro servizio REST.
Ultima feature che possiamo configurare è l auto-healing: possiamo configurare un health check che permetta all autoscaler di valutare se le VM sono in salute; qualora una VM non sia in salute l autoscaler provvederà a terminarla e a lanciarne una nuova.

Come evidenziato nello screen, abbiamo configurato come health check uno scheduler che spara richieste HTTP ogni 10 secondi al path /hello in modo da valutare se il servizio risponde o non e in caso di 3 richieste in timeout il servizio viene considerato come in cattiva salute e la VM viene stoppata e ricreata.
3- cloud load balancing
Ci siamo ragazzi, adesso possiamo andare a configurare il servizio cloud load balancing che avrà il compito di:
- fare da frontend per le VM dove gira il nostro servizio. In altre parole il servizio di load balancing sarà l unico indirizzo pubblico che avremo nella nostra architettura.
- inoltrare le richieste dal load balancing a una delle VM disponibili nel gruppo bilanciando il carico tra le VM in salute nel gruppo.
Procediamo a scegliere la prima opzione proposta nel form di creazione load balancer perché stiamo andando a creare un load balancer esposto su internet.

A questo punto il form ci riassume le 3 fasi di configurazione del load balancer

Iniziamo con la configurazione del backend del load balancer.
3.1 Backend configuration
Il servizio di backend definisce il modo in cui Cloud Load Balancing distribuisce il traffico. La configurazione del servizio di backend contiene una serie di valori, come il protocollo utilizzato per connettersi ai backend, varie impostazioni di distribuzione e sessione, controlli di integrità e timeout. Queste impostazioni forniscono un controllo dettagliato sul comportamento del bilanciatore del carico.

In rilievo nelle impostazioni scelte:
- il link alla named port precedentemente definita: la porta 8080 dove gira il servizio REST
- abbiamo scelto il nostro instance group come backend del load balancing.
- Regole di bilanciamento come Max backend utilization per escludere dalle VM candidate a gestire le richieste le VM che hanno il carico di CPU più alto del 80%
- Eventuale configurazione di Cloud Armor e CDN
3.2 host and path rules
3.3 CONFIGURAZIONE FRONTEND
Il frontend del Load Balancing sarà l interfaccia esposta su internet che i vostri client interrogheranno per accedere alle vostre API. Sarà quindi il punto di accesso per il nostro servizio e quindi in questa fase andremo a creare l indirizzo IP: possiamo scegliere Ephemeral o statico; se selezionate l opzione effimera l’IP potrebbe cambiare con il tempo e quindi non è consigliato per ambienti di produzione.

A questo punto controllate il riepilogo e confermate la creazione del load balancing

TEST
Una volta confermato la creazione del Load balancer, attendete che sulla dashboard il servizio sia UP&Running e infine provate a sparare una richiesta HTTP verso l indirizzo pubblico del frontend del Load Balancer.
$ curl http://130.211.44.126/hello hello by instance:rest-hello-group-gwb4
Come si evince dalla risposta l esito ha avuto esito positivo: il frontend ha inoltrato correttamente la richieste alla porta 8080 (named port definita) dell’unica VM presente nel gruppo la quale ha risposto con il messaggio di hello world. Se volete testare l autoscaling, divertiamoci a forzare il livello della CPU utilizzata dalla VM del gruppo utilizzando i tips suggeriti da questo articolo. Potrete notare dalla pagina di dettaglio del vostro instance group che l autoscaler si è accorto che la CPU della vostra VM ha un carico troppo elevato e dopo pochi istanti verrà aggiunta una seconda VM per bilanciare il carico con un numero maggiore di VM. Se terminate il forcing della CPU sulla prima VM, la VM tornerà in “salute” e dopo 10 minuti (tempo di assestamento di default) la seconda VM verrà terminata.