
Prima regola del Deep Learning Club:
non puoi usare il Deep Learning se non sai come funziona una Rete Neurale Artificiale.
Quando ci si approccia per la prima volta a Deep Learning e Reti Neurali si viene subito intimoriti dalla matematica che c’è dietro e si finisce a guardare le API di Tensorflow o a fare copia-incolla di pezzi di codice presi in giro per il web aggiungendo strati su strati, come dicevano gli scienziati dell’antica Roma, ad mentula canis.
Lo scopo di questo articolo è demistificare la complessità delle Reti Neurali e mostrare che in fondo, se si sa come interpretarla, la matematica che c’è dietro non è nulla di terrificante.
Premesse
- In questo tutorial creeremo una Shallow Neural Network, cioè una Rete Neurale con un’unico strato nascosto. Ampliare la Rete Neurale al caso di strati nascosti multipli non è per nulla complesso, a livello matematico non cambia nulla, a livello di codice bisogna lavorare un po’ di più. Prova a farlo come esercizio, oppure se vuoi vedere una mia implementazione fammelo sapere nei commenti.
- La rete che andremo a creare è per problemi di classificazione binaria, quindi quando dobbiamo distinguere un caso positivo da uno negativo (es. distinguere uomo da donna), se vogliamo utilizzarla per altri tipi di problemi, come la classificazione multiclasse o la regressione, dobbiamo soltanto modificare la funzione di attivazione sullo strato di output e la funzione di costo che utilizziamo. Anche qui, se vuoi vedere degli esempi ad-hoc, fammelo sapere.
Prerequisiti
- In questo tutorial implementeremo una Rete Neurale da Zero con Python usando soltanto Numpy, popolare libreria per il calcolo numerico che ci permette di operare su matrici e vettori. Se sei un programmatore ma non conosci Python dai uno sguardo al mio articolo Programmazione con Python: le 10 Cose da Sapere. Se non sai proprio nulla di programmazione puoi partire con il mio corso gratuito di un’ora e mezza Programmazione con Python in 90 minuti.
- In questo tutorial darò per scontato che tu sappia cosa è e a cosa serve il Machine Learning, se non lo sai dai uno sguardo al mio articolo Cosa è il Machine Learning.
- Conoscere come funziona una Rete Neurale Artificiale, anche ad un livello molto intuitivo, ti può agevolare a seguire questo tutorial, dai uno sguardo all’articolo Deep Learning Svelato: ecco come funziona una Rete Neurale Artificiale.
- Un po’ di matematica la devi sapere, sennò dove vuoi andare eh ?
Creiamo una classe per la nostra Rete Neurale
Creiamo una classe NeuralNetwork, nel costruttore passeremo soltanto un parametro hidden_layer_size, che conterrà il numero di nodi (o neuroni) dello strato nascosto.
class NeuralNetwork:
def __init__(self, hidden_layer_size=100):
self.hidden_layer_size=hidden_layer_size
Iniziamo con qualche Metrica
Le metriche sono un’argomento generale di un qualsiasi modello Machine Learning e non limitate alle sole Reti Neurali, queste ci permettono di determinare la qualità del nostro modello comparando le predizioni da esso fornite con i risultati reali presenti all’interno del dataset.
Una metrica comune per problemi di classificazione è l’accuracy che in sostanza indica semplicemente la percentuale di predizioni che il nostro modello ha azzeccato e, senza voler utilizzare probabilità condizionali, possiamo definire così:
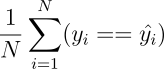
dove 𝑦̂ è il vettore con le predizioni del modello mentre 𝑦 è il vettore con i valori reali.
∑ è il simbolo della sommatoria, ad esempio
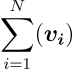
ci tonerà la somma di tutti gli N valori all’interno del vettore v.
L’accuracy è una funzione di scoring che ritorna un valore compreso tra 0 e 1, dove un valore maggiore indica una qualità migliore del modello (eccezion fatta per casi di overfitting, ma di questo parleremo più avanti).
Aggiungiamo alla classe un metodo per calcolare l’accuracy.
def _accuracy(self, y, y_pred): return np.sum(y==y_pred)/len(y)
Una riga di codice ? Che stregoneria è mai questa ? Questa stregoneria si chiama vettorizzazione ed è la proprietà più figa di Numpy, che ci permette di eseguire operazioni tra vettori, il risultato di y==y_pred è quindi un nuovo vettore che conterrà un 1 nelle posizioni in cui i due vettori hanno lo stesso valore, 0 altrimenti. Utilizzando la funzione sum sommiamo tutti i valori all’interno di questo vettore e infine dividiamo per il numero di osservazioni.
Uno dei limiti di questa metrica è che non tiene conto della probabilità che una predizione sia corretta, quindi un’errore grossolano assume lo stesso peso di un’errore minore. Per questo motivo è sempre una buona idea affiancare l’accuracy ad un altra metrica che tiene conto di questa informazione, cioè la Cross Entropy anche conosciuta come Log Loss, che è definita in questo modo:
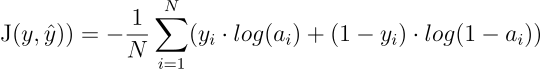
dove a sono le probabilità di appartenenza alla classe positiva ritornate dal modello, mentre y sono sempre i valori reali.
A differenza dell’accuracy, la log loss è una funzione di costo, quindi un suo valore minore indica una migliore qualità del modello.
Definiamo un metodo per calcolare la Log Loss:
def _log_loss(self, y_true, y_proba): return -np.sum(np.dot(y_true,np.log(y_proba))+np.dot((1-y_true),np.log(1-y_proba)))/len(y_true)
Dot è il prodotto scalare tra due vettori, che è così definito:
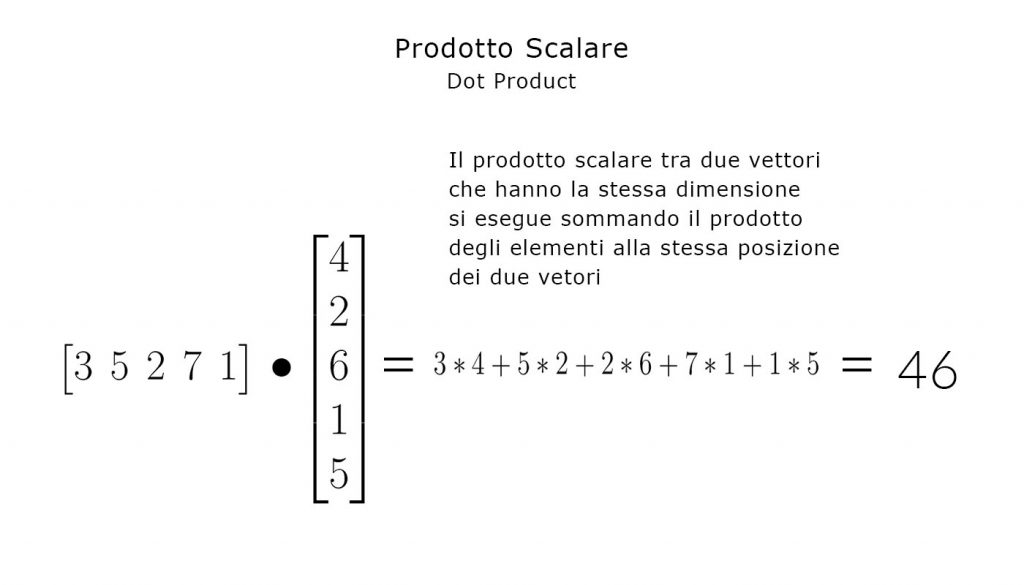
E in quanto a metriche ci siamo, passiamo alla fase di predizione.
La Predizione
La predizione è la fase in cui utilizziamo i coefficienti appresi dal modello per classificare una data osservazione. In un modello lineare, come la regressione logistica, la classificazione avviene semplicemente moltiplicando le features dell’osservazione con i rispettivi pesi e sommando il bias, per poi far passare tale valore attraverso una funzione di attivazione (della quale parleremo dopo).
In una Rete Neurale il discorso è più complesso, abbiamo più coefficienti disposti su più strati disposti in sequenza, nel caso di una Shallow Neural Network abbiamo tre strati, uno di input, uno nascosto e uno di output, 2 matrici di pesi, una che collega ogni nodo dello strato input ad ogni neurone dello strato nascosto e una che collega ogni nodo dello strato nascosto all’unico nodo dello strato di output, oltre ovviamente ai due rispettivi vettori con i bias, che vengono sempre trascurati :(.
In una rete neurale la predizione avviene a cascata, l’input della rete arriva allo strato di input, viene moltiplicato per i pesi dello strato e viene sommato il bias in questo modo:
![]()
In questo caso abbiamo fatto uso di matrici e vettori, il prodotto tra W_1 e x è un prodotto scalare tra matrici (in realtà tra una matrice e un vettore in questo caso, ma il discorso è lo stesso) ed è così definito:

Ora l’output dello strato di input diventerà l’input dello strato nascosto, questo processo è conosciuto come Forward Propagation (Propagazione in Avanti) e queste sono le sue equazioni:
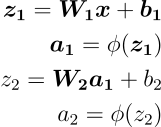
i vari vettori z sono gli output lineari dello strato, anche chiamati net input, come vedi a questi vettori viene applicata una funzione 𝛷, questa funzione è la funzione di attivazione di cui parlavamo prima e ci permette di aggiungere la non linearità alla nostra rete, senza di essa una rete neurale, anche una molto profonda, porterebbe agli stessi risultati di un semplice modello lineare come la regressione logistica.
Esistono diverse funzioni di attivazione e variano in base al tipo di strato, per gli strati nascosti la più utilizzata e la Rectified Linear Unit (ReLu) che è così definita:
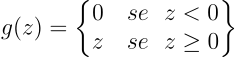
Implementiamola in un metodo della nostra classe
def _relu(self, Z): return np.maximum(Z, 0)
Per gli strati di output la funzione di attivazione da utilizzare dipende dal tipo di problema che stiamo affrontando, per una classificazione binaria bisogna usare la sigmoide, che è così definita.
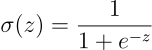
Implementiamo un metodo anche per la sigmoide
def _sigmoid(self, Z): return 1/(1+np.power(np.e,-Z))
Aggiungendo le corrette funzioni di attivazione, le equazioni della Forward Propagation diventano le seguenti:
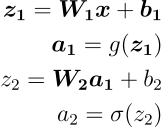
Usiamo le equazioni per implementare un metodo per la Forward Propagation.
def _forward_propagation(self, X):
Z1 = np.dot(X,W1)+b1
A1 = relu(Z1)
Z2 = np.dot(A1,W2)+b2
A2 = sigmoid(Z2)
self.cache = (Z1, A1, Z2, A2)
# usiamo il metodo .ravel()
# per convertire A2 in un array 1D
return A2.ravel()
Che è quella cache dove salviamo i risultati intermedi della rete ? Di questo parleremo più avanti, per adesso fidati.
Ora, l’ultimo strato ci ritorna la probabilità che l’osservazione in input appartenga alla classe positiva:
- un’osservazione con una probabilità maggiore del 50% va classificata come appartenenza alla classe positiva
- un’osservazione con probabilità minore del 50% va classificata come appartenente alla classe negativa.
Questo nel caso standard, poi possiamo anche variare in base ai nostri obiettivi di precision e recall, ma questo merita un’articolo a parte.
Per standard, qualora la probabilità fosse esattamente del 50% classifichiamola come positiva, anche se non è attendibile, in ogni caso insieme ad una classificazione dobbiamo sempre prendere in considerazione la probabilità della sua correttezza.
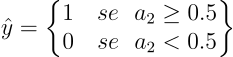
Utilizziamo queste informazioni per creare il metodo per eseguire la predizione.
def predict(self, X):
proba = self._forward_propagation(X)
y = np.zeros(X.shape[0])
y[proba>=0.5]=1
y[proba<0.5]=0
return y
In base a quanto detto, definiamo anche un metodo per ottenere la probabilità, che poi non sarà altro che un’alias del metodo _forward_propagation.
def predict_proba(self, X):
return self._forward_propagation(X)
La fase di predizione è completa, passiamo all’addestramento, dove permetteremo alla nostra rete di apprendere i sui coefficienti dai dati in maniera autonoma.
L’Addestramento
L’addestramento della maggior parte dei modelli di machine learning si basa sull’utilizzo di un algoritmo di ottimizzazione, il più comune è il Gradient Descent.
Gradient Descent in Matematichese
Il funzionamento di questo algoritmo è abbastanza semplice: al valore di ogni coefficiente viene iterativamente sottratto il valore della derivata parziale della funzione di costo rispetto al coefficiente moltiplicata per una costante, chiamata Learning Rate, e questo per un numero definito di cicli, chiamati epoche.
Okay, detto così potrebbe non sembrare facile affatto, specialmente se non ricordi cosa è una derivata, quindi facciamo un piccolo ripasso di analisi matematica.
Facciamo un passo indietro: derivate e gradienti
La derivata di una funzione è un’altra funzione derivata da essa (e da qui il nome) che indica quanto velocemente la funzione sta crescendo/decrescendo in un determinato punto.
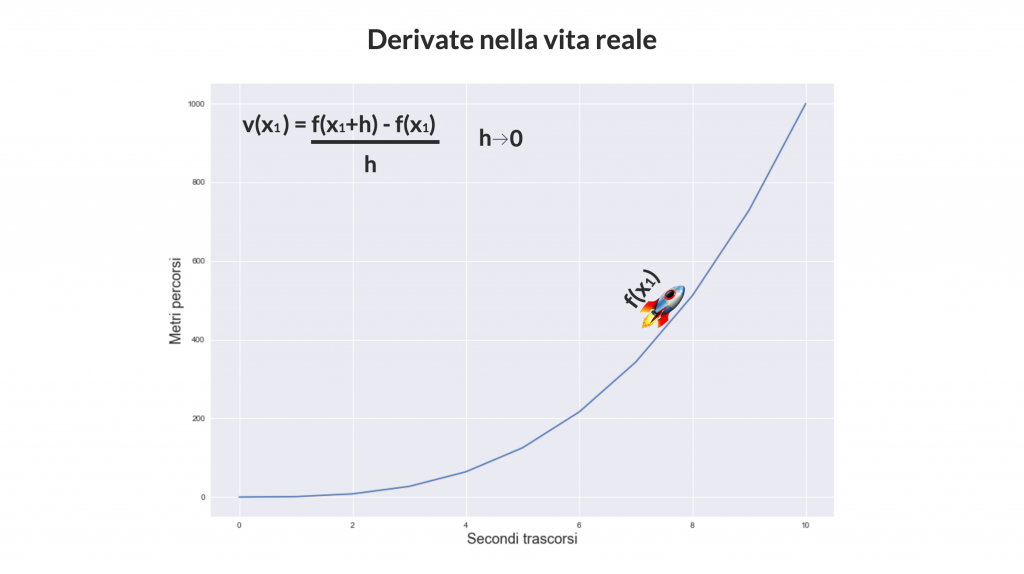
Se in un dato punto la funzione sta crescendo in maniera molto rapida, la sua derivata sarà un valore positivo grande, al contrario se la funzione sta decrescendo in maniera molto rapida la sua derivata sarà un valore negativo molto grande. Se invece la funzione è costante, quindi mantiene lo stesso valore, allora la derivata varrà 0.
Esistono 3 diversi tipi di notazioni per indicare una derivata: la notazione di Lagrange, quella di Newton e quella di Leibniz.
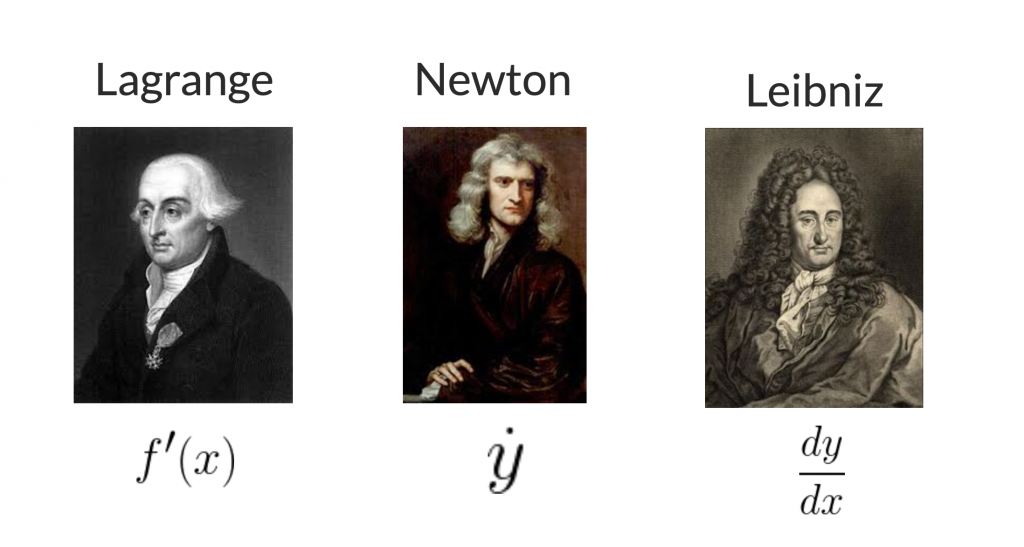
In questo tutorial useremo quella di Leibniz, che poi è quella più utilizzata nel caso di funzioni a più variabili.
Parlando di funzioni a più variabili, se una funzione ha più variabili allora ha più derivate, dato che ogni variabile può contribuire alla variazione della funzione in maniera differente, in questo caso si parla di derivate parziali, che messe insieme formano il gradiente della funzione, che si indica con il simbolo nabla (il triangolo sotto sopra che vedi qui sotto)
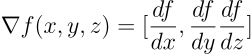
Ora che abbiamo rispolverato le derivate, torniamo al Gradient Descent.
Gradient Descent in Italiano
In parole povere il Gradient Descent funziona così: i valori ‘ideali’ dei coefficienti sono quelli che ci permettono di ottenere il valore minore per la funzione di costo, cioè quelli che la minimizzano, sommando iterativamente il valore delle rispettive derivate parziali della funzione di costo tendiamo a ‘spingere’ i coefficienti verso tale punto di minimo.
Il learning rate ci permette di impostare la forza di tale spinta, o meglio la dimensione di ogni step (epoca) del Gradient Descent.
Probabilmente non giungeremo mai ai coefficienti ideali, ma utilizzando un numero sufficiente di epoche potremmo riuscire a stimarli con un buon grado di approssimazione.
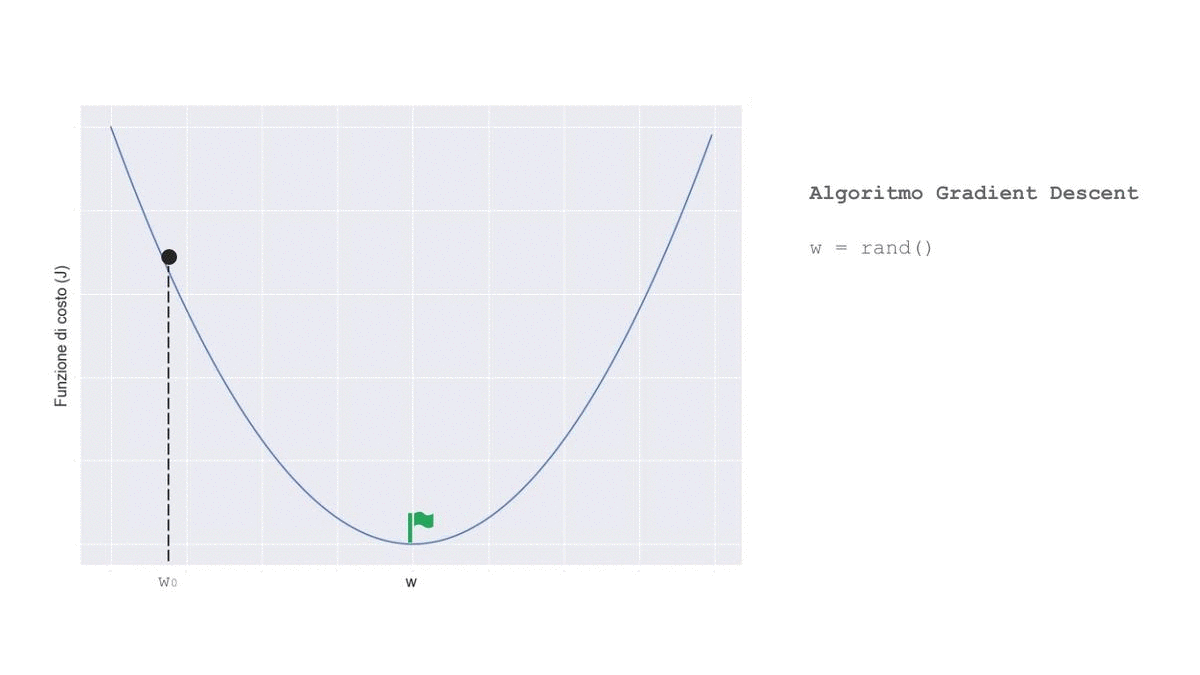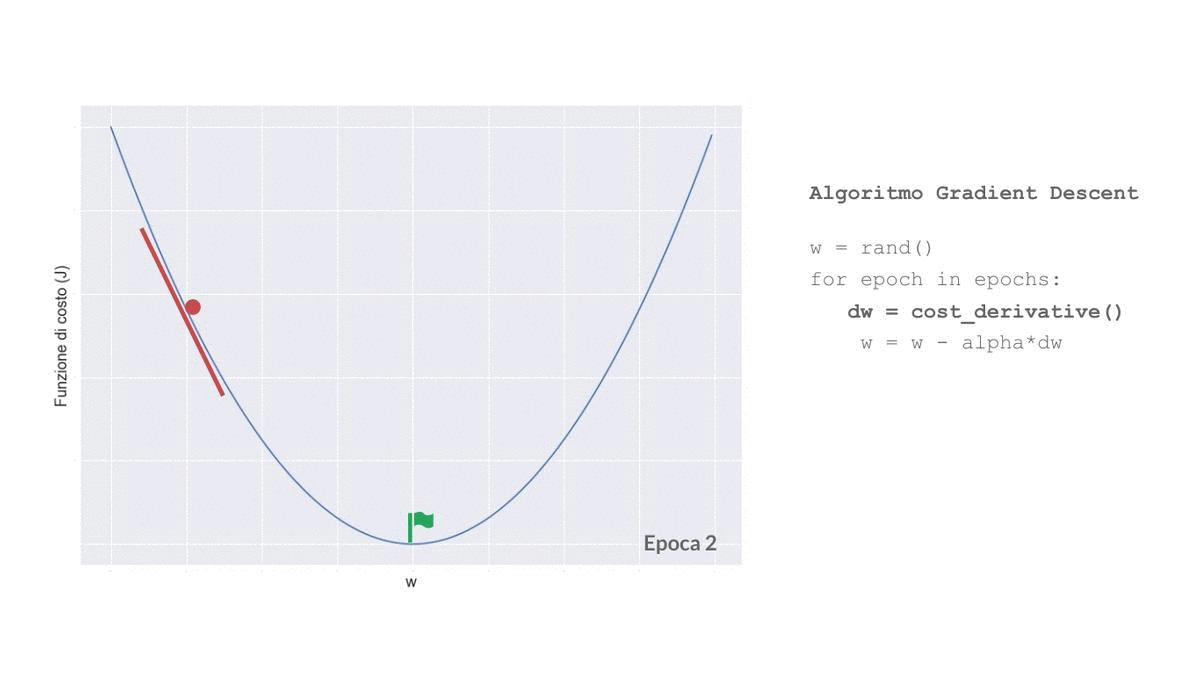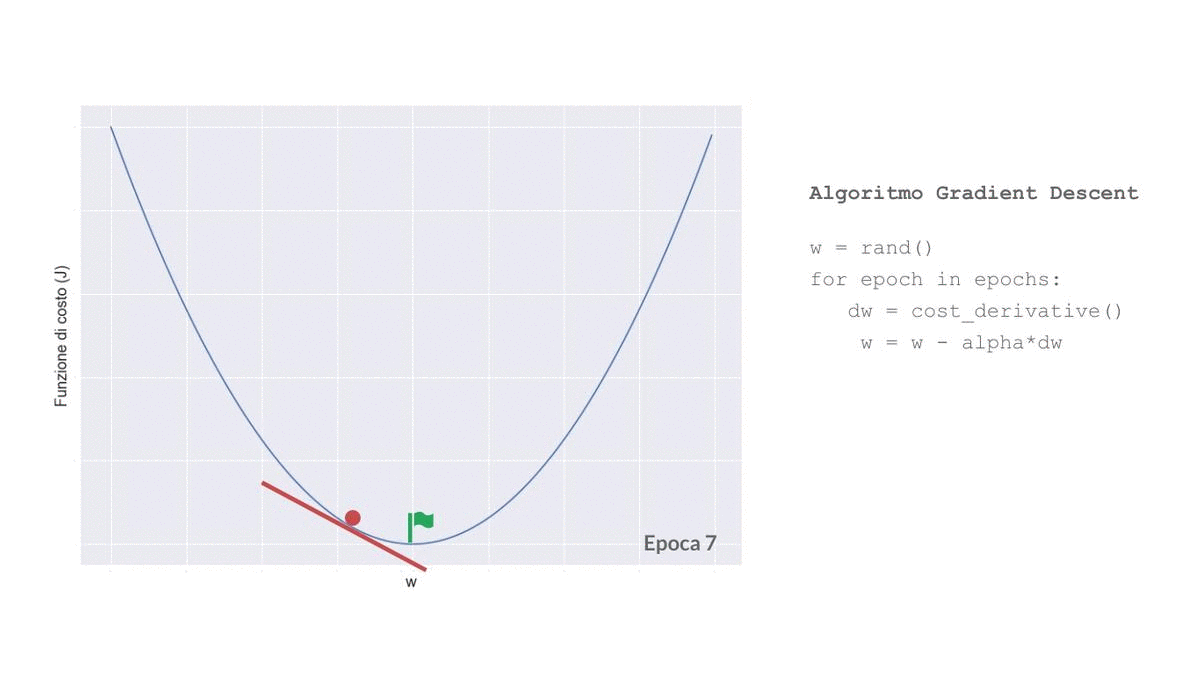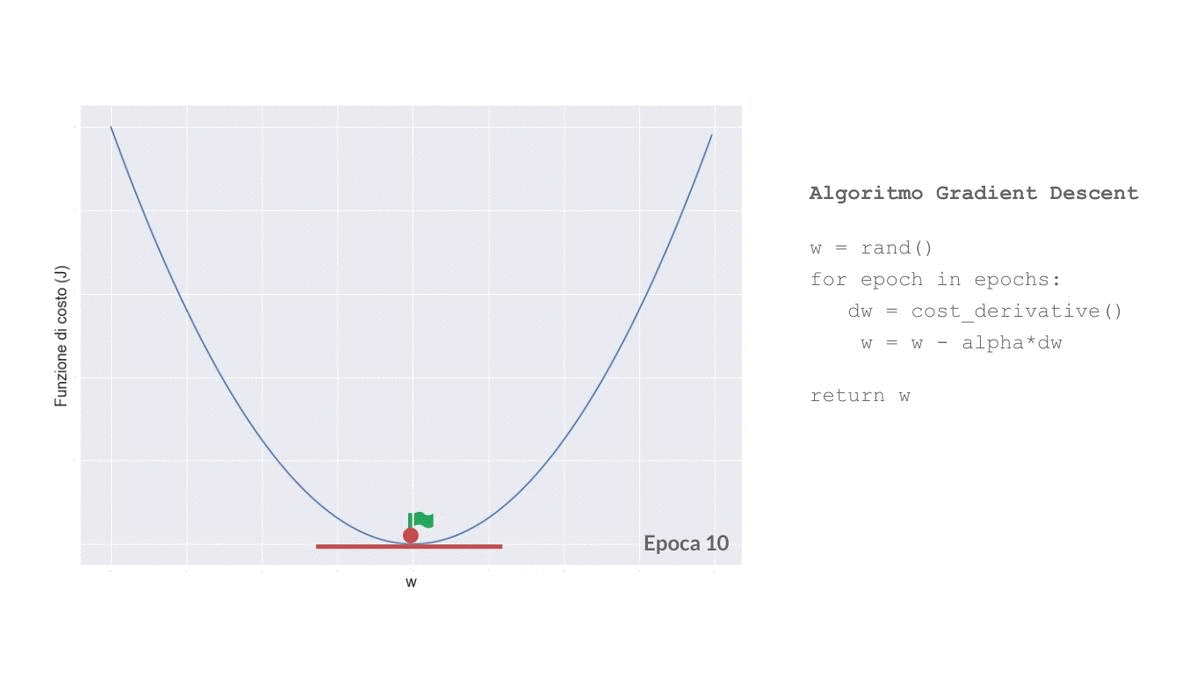
Implementiamo il Gradient Descent per la nostra Rete Neurale, per adesso ignora la funzione per calcolare le derivate parziali, ci arriveremo tra pochissimo:
def fit(self, X, y, epochs=200, lr=0.01):
for _ in range(epochs):
Y = self._forward_propagation(X)
dW1, db1, dW2, db2 = self._funzione_magica_che_calcola_le_derivate_parziali(X, y)
self._W1-=lr*dW1
self._b1-=lr*db1
self._W2-=lr*dW2
self._b2-=lr*db2
Learning Rate e numero di Epoche sono due dei tanti iperparametri di una rete neurale, cioè quei valori che tocca a noi definire manualmente.
Per una rete neurale il numero di epoche andrebbe sempre impostato almeno a 100, mentre il Learning Rate va cercato in uno spazio di potenze di 10 che va da 10 elevato alla -4 (0.0001) a 10.
Calcolare il Gradiente: il Grande Dilemma
Come facciamo a calcolare il gradiente, cioè le derivate parziali della funzione di costo rispetto ai vari coefficienti ? Come si dice da me “e qua casca lo scecco” !
Se si fosse trattato di una regressione logistica, differenziare la funzione di costo sarebbe stato un gioco da ragazzi della quinta liceo classico rimandati per tre anni di fila in matematica, ma nel caso di una rete neurale è molto più complesso, infatti una rete neurale è formata da più funzioni composte, cioè funzioni che hanno come argomento altre funzioni, se non ci credi pensa che le equazioni della forward propagation possono anche essere espresse come un’unica equazione incomprensibile, questa qui nel caso di una Shallow Neural Network
![]()
dove con g intendiamo la funzione ReLu.
Ora noi dobbiamo riuscire a sapere quanto ogni coefficiente di ogni strato contribuisce all’errore della rete e questo problema non è per nulla banale ! Infatti gli scienziati ci si sono arrovellati sopra per 50 anni, fino al 1984, quando si arrivò ad una soluzione, la Backpropagation (propagazione all’indietro o retropropagazione).
L’algoritmo della Backpropagation
La Backpropagation è il processo inverso della Forward Propagation, questa volta l’output della rete va a ritroso dall’ultimo strato fino al primo. In realtà ad andare a ritroso non è l’output ma l’errore e in questo modo riusciamo a risalire a quanto ogni coefficiente di ogni strato ha contribuito all’errore.
Ma come ? Ma perché ?
L’algoritmo si basa su una proprietà delle derivate, chiamata Chain Rule (Regola della Catena), che ci dice che la derivata di una funzione composta è pari al prodotto della derivata più esterna, avente come argomento la funzione interna, per la derivata della funzione interna.
Quindi se abbiamo una funzione f(x) tale che:
f(x) = f(g(x))
che quindi è una funzione composta, possiamo calcolare la sua derivata come
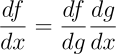
Utilizzando tale proprietà possiamo propagare il segnale all’indietro (e qui il nome) e calcolare le varie derivate parziali, per adesso ti risparmio i calcoli, che ti sto già riempiendo la testa di numeri e variabili, ma qualora ti interessasse vederli fammelo sapere nei commenti e se siete un po’ di persone a chiederli li ricopierò in digitale.
Applicando la chain rule, otteniamo le seguenti equazioni per il calcolo delle derivate parziali
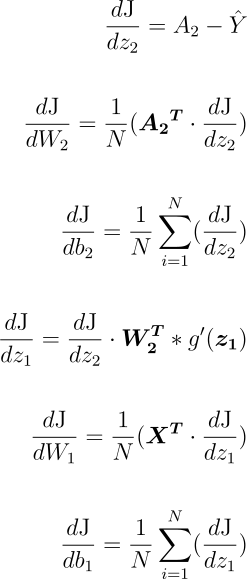
Ricordi la cache con i risultati intermedi della forward propagation ? Bene è qui che ci serve ! Infatti come vedi per poter eseguire la backpropation, e quindi per poter applicare la chain rule, abbiamo bisogno di questi valori.
Alcune osservazioni sulle equazioni:
- X è la matrice con gli esempi che utilizziamo per addestrare la rete neurale, ogni colonna rappresenta una feature e ogni riga contiene un’esempio.
- La T all’apice indica la matrice trasposta, cioè la matrice ottenuta invertendo le righe con le colonne.
- g'(z1) è la derivata della funzione ReLu rispetto a z1 (in questo caso abbiamo usato la notazione di Lagrange) che è la seguente:
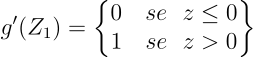
Abbiamo tutto ciò che ci serve per implementare la backpropagation, mettiamoci all’opera
def _relu_derivative(self, Z):
dZ = np.zeros(Z.shape)
dZ[Z>0] = 1
return dZ
def _back_propagation(self, X, y):
Z1, A1, Z2, A2 = self._forward_cache
m = A1.shape[1]
dZ2 = A2-y.reshape(-1,1) # il reshape ci serve per far combaciare le dimensioni dei due vettori
dW2 = np.dot(A1.T, dZ2)/m
db2 = np.sum(dZ2, axis=0)/m
dZ1 = np.dot(dZ2, self._W2.T)*self._relu_derivative(Z1)
dW1 = np.dot(X.T, dZ1)/m
db1 = np.sum(dZ1, axis=0)/m # eseguiamo la somma lungo le righe
return dW1, db1, dW2, db2
All’interno della metodo fit sostituiamo la funzione_magica_per_calcolare_le_derivate_parziali con la back_propagation che abbiamo appena definito:
def fit(self, X, y, epochs=200, lr=0.01):
for _ in range(epochs):
Y = self._forward_propagation(X)
dW1, db1, dW2, db2 = self._back_propagation(X, y)
self._W1-=lr*dW1
self._b1-=lr*db1
self._W2-=lr*dW2
self._b2-=lr*db2
Fantastico, ci siamo quasi ! Manca solo un’ultimo passaggio, l’inizializzazione dei coefficienti.
Possiamo inizializzare i bias a 0, ma non i pesi ! Inizializzando i pesi a 0 le derivate parziali di tutti i pesi avranno lo stesso valore per tutte le iterazioni, questo vuol dire che il nostro modello non sarà migliore di un modello lineare.
- I pesi andrebbero inizializzati a valori casuali né troppo grandi né troppo piccoli, infatti:
Se i pesi vengono inizializzati a valori troppo grandi, nel caso di una rete abbastanza profonda il gradiente diventerà ancora più grande, a causa delle varie moltiplicazioni tra valori elevati alla quale è soggetto, questo problema è chiamato Exploding Gradient Problem (Problema dell’esplosione del Gradiente). - Se i pesi vengono inizializzati a valori troppo piccoli il problema è l’inverso, durante la backpropagation calcoleremo il gradiente eseguendo delle moltiplicazioni per valori molto piccoli, quindi questo tenderà a ridursi verso lo zero, questo problema è chiamato Vanishing Gradient Problem (Problema della Scomparsa del Gradiente).
Esistono tecniche sofisticate per l’inizializzazione intelligente dei pesi, ma nel nostro caso stiamo realizzando una rete neurale con un solo strato nascosto, quindi non dovremmo preoccuparci di questi problemi, selezioniamo i pesi da una semplice distribuzione normale, cioè una distribuzione con media pari a 0 e deviazione standard pari a 1.
def _init_weights(self, input_size, hidden_size):
self._W1 = np.random.randn(input_size, hidden_size)
self._b1 = np.zeros(hidden_size)
self._W2 = np.random.randn(hidden_size,1)
self._b2 = np.zeros(1)
Aggiungiamo l’inizializzazione dei coefficienti all’inizio del metodo fit
def fit(self, X, y, epochs=200, lr=0.01):
self._init_weights(X.shape[1], self.hidden_layer_size)
for _ in range(epochs):
Y = self._forward_propagation(X)
dW1, db1, dW2, db2 = self._back_propagation(X, y)
self._W1-=lr*dW1
self._b1-=lr*db1
self._W2-=lr*dW2
self._b2-=lr*db2
Questo è tutto, la nostra Rete Neurale è pronta !
La Rete Neurale al completo
Questa è la nostra classe Neural Network al completo, l’unica dipendenza che usiamo è Numpy:
import numpy as np
class NeuralNetwork:
def __init__(self, hidden_layer_size=100):
self.hidden_layer_size=hidden_layer_size
def _init_weights(self, input_size, hidden_size):
self._W1 = np.random.randn(input_size, hidden_size)
self._b1 = np.zeros(hidden_size)
self._W2 = np.random.randn(hidden_size,1)
self._b2 = np.zeros(1)
def _accuracy(self, y, y_pred):
return np.sum(y==y_pred)/len(y)
def _log_loss(self, y_true, y_proba):
return -np.sum(np.multiply(y_true,np.log(y_proba))+np.multiply((1-y_true),np.log(1-y_proba)))/len(y_true)
def _relu(self, Z):
return np.maximum(Z, 0)
def _sigmoid(self, Z):
return 1/(1+np.power(np.e,-Z))
def _relu_derivative(self, Z):
dZ = np.zeros(Z.shape)
dZ[Z>0] = 1
return dZ
def _forward_propagation(self, X):
Z1 = np.dot(X,self._W1)+self._b1
A1 = self._relu(Z1)
Z2 = np.dot(A1,self._W2)+self._b2
A2 = self._sigmoid(Z2)
self._forward_cache = (Z1, A1, Z2, A2)
return A2.ravel()
def predict(self, X, return_proba=False):
proba = self._forward_propagation(X)
y = np.zeros(X.shape[0])
y[proba>=0.5]=1
y[proba<0.5]=0
if(return_proba):
return (y, proba)
else:
return proba
def _back_propagation(self, X, y):
Z1, A1, Z2, A2 = self._forward_cache
m = A1.shape[1]
dZ2 = A2-y.reshape(-1,1)
dW2 = np.dot(A1.T, dZ2)/m
db2 = np.sum(dZ2, axis=0)/m
dZ1 = np.dot(dZ2, self._W2.T)*self._relu_derivative(Z1)
dW1 = np.dot(X.T, dZ1)/m
db1 = np.sum(dZ1, axis=0)/m
return dW1, db1, dW2, db2
def fit(self, X, y, epochs=200, lr=0.01):
self._init_weights(X.shape[1], self.hidden_layer_size)
for _ in range(epochs):
Y = self._forward_propagation(X)
dW1, db1, dW2, db2 = self._back_propagation(X, y)
self._W1-=lr*dW1
self._b1-=lr*db1
self._W2-=lr*dW2
self._b2-=lr*db2
def evaluate(self, X, y):
y_pred, proba = self.predict(X, return_proba=True)
accuracy = self._accuracy(y, y_pred)
log_loss = self._log_loss(y, proba)
return (accuracy, log_loss)
Ho fatto solo due piccole modifiche:
- Ho rimosso il metodo predict_proba e ho piuttosto aggiunto un parametro return_proba al metodo predict, per ritornare opzionalmente anche le probabilità oltre che le classi predette senza dover fare due volte il calcolo.
- Ho creato un metodo evaluate, che in un solo colpo esegue le predizioni, calcola le metriche e le ritorna.
Testiamo la Rete Neurale
In questo tutorial, abbiamo creato un modello di regressione logistica per riconoscere tumori al seno maligni, partendo da informazioni estratte da esami radiologici.
Utilizziamo lo stesso dataset per testare la nostra rete neurale, questa volta facendo totalmente a meno di scikit-learn.
Importiamo il dataset direttamente dalla Repository Github dei Tutorial di ProfessionAI, per farlo possiamo utilizzare Pandas, una popolare libreria Python per l’analisi dati.
import pandas as pd CSV_URL = "https://raw.githubusercontent.com/ProfAI/tutorials/master/Come%20Creare%20una%20Rete%20Neurale%20da%20Zero/breast_cancer.csv" breast_cancer = pd.read_csv(CSV_URL)
Il risultato sarà un DataFrame, una struttura dati che Pandas usa per rappresentare dati tabulari, possiamo avere una preview del suo contenuto usando il metodo .head().
Il nostro dataset contiene in totale 563 righe (e quindi esempi) e 31 colonne, cioè 30 features e un target, che è la colonna “malignant”.
Estraiamo features e target in array numpy.
X = breast_cancer.drop("malignant", axis=1).values
y = breast_cancer["malignant"].values
Ora dobbiamo dividere ogni array in due array distinti, uno per l’addestramento e uno per il test. Questa divisione serve per poter verificare le reali capacità predittive del modello, testandolo su dati che non ha già visto durante la fase di addestramento.
L’overfitting di cui abbiamo accennato all’inizio è la condizione in cui il modello memorizza i dati di addestramento piuttosto che apprendere da essi, avere un set di test separato ci permette di identificare questa situazione.
Creiamo una funzione train_test_split per eseguire questa divisione:
def train_test_split(X, y, test_size=0.3, random_state=None):
if(random_state!=None):
np.random.seed(random_state)
n = X.shape[0]
test_indices = np.random.choice(n, int(n*test_size), replace=False) # selezioniamo gli indici degli esempi per il test set
# estraiamo gli esempi del test set
# in base agli indici
X_test = X[test_indices]
y_test = y[test_indices]
# creiamo il train set
# rimuovendo gli esempi del test set
# in base agli indici
X_train = np.delete(X, test_indices, axis=0)
y_train = np.delete(y, test_indices, axis=0)
return (X_train, X_test, y_train, y_test )
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Abbiamo assegnato il 30% degli esempi del dataset al set di test, quindi abbiamo 395 esempi per l’addestramento e 168 per il test, sono un po’ pochi per l’addestramento di una rete neurale, ma trattandosi di un modello con un solo strato nascosto possono andare bene.
E’ buona norma portare le features in un range di valori comune, questo può velocizzare anche di tanto la fase di addestramento.
Utilizziamo la normalizzazione, che si esegue sottraendo il valore minore e dividendo per la differenza tra il valore maggiore e il valore minore:
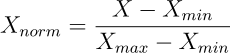
Ricorda che dobbiamo sempre applicare le stesse trasformazioni ai dati di addestramento, a quelli di test, e in generale a tutti quelli che daremo in pasto alla nostra rete neurale, quindi calcoliamo massimo e minimo sul set di addestramento e usiamo questi valori per la normalizzazione di entrambi gli array.
X_max = X_train.max(axis=0) X_min = X_train.min(axis=0) X_train = (X_train - X_min)/(X_max-X_min) X_test = (X_test - X_min)/(X_max-X_min)
Perfetto ! Adesso creiamo la nostra rete con 10 nodi sullo strato nascosto, addestriamola sul set di addestramento per 500 epoche e valutiamola sul set di test.
model = NeuralNetwork() model.fit(X_train, y_train, epochs=500, lr=0.01) model.evaluate(X_test, y_test)
I risultati che ho ottenuto io sono circa 0.981 di accuracy e circa 0.089 di log loss, dato che i pesi vengono inizializzati a valori casuali il risultato può lievemente variare tra diverse esecuzioni della rete.
La Rete Neurale funziona. E ora ?
Mettiamo caso di ricevere i risultati di 6 nuovi esami radiografici, le features estratte da questi ci vengono consegnate all’interno di un file csv, carichiamolo con pandas, estraiamolo le features e normalizziamole
exams_df = pd.read_csv("https://raw.githubusercontent.com/ProfAI/tutorials/master/Come%20Creare%20una%20Rete%20Neurale%20da%20Zero/exam%20results.csv")
X_new = exams_df.values
X_new = (X_new - X_min)/(X_max-X_min)
Ora utilizziamo il metodo predict per classificare i risultati di tali esami, in modo da identificare eventuali tumori maligni, ottenendo anche la probabilità
y_pred, y_proba = model.predict(X_new, return_proba=True)
Stampiamo il risultato.
classes = ["benigno", "maligno"]
for i, (pred, proba) in enumerate(zip(y_pred, y_proba)):
print("Risultato %d = %s (%.4f)" % (i+1, classes[int(pred)], proba))
"""
Risultato 1 = benigno (0.0000)
Risultato 2 = maligno (0.9982)
Risultato 3 = maligno (0.9982)
Risultato 4 = benigno (0.0103)
Risultato 5 = maligno (0.6891)
Risultato 6 = benigno (0.0316)
"""
Quando la probabilità associata non è alta andrebbero eseguiti ulteriori esami di verifica, specialmente nel caso di un tumore classificato come benigno, dato che classificare erroneamente un tumore maligno come benigno è molto più grave che classificare un tumore benigno come maligno.
Come abbiamo visto in questo tutorial, in questi casi è opportuno utilizzare anche la matrice di confusione come metrica per valutare il modello.
Complimenti ! Hai creato la tua Rete Neurale Artificiale da Zero
Siamo arrivati alla fine di questo tutorial e ora sappiamo come creare una Rete Neurale da zero facendo a meno di framework per il Deep Learning, facciamo solo un’ultima considerazione finale.
Realizzare una Rete Neurale da zero in questo modo può essere davvero utile a fini didattici, per riuscire a comprendere appieno come questa funziona al suo interno e l’effetto che hanno i vari parametri e iperparametri, però per progetti che devono andare in produzione non dovresti mai, per nessun motivo, fare una cosa dal genere, ma piuttosto puoi affidarti a framework affermati, aggiornati e supportati dalle grosse aziende del Tech, l’esempio per eccellenza è Tensorflow.
