
Il deploy
Per molti sarà scontato, ma chi segue ciò che scrivo o che comunque ha già letto qualche altro mio post, sa che non mi piace molto lasciare i temi cardine di un articolo all’intuizione o ai pareri personali. Quindi, pur di risultare noioso o scontato, definiamo da subito il significato della parola “deploy” che utilizzerò da questo punto in poi:
Il deploy è un processo fondamentale nel percorso finale di creazione e sviluppo di una qualunque applicazione. E’ quella che può essere considerata, in via definitiva, la pubblicazione del prodotto. Tra tutte le versioni generate per testing, sviluppo e altri scopi, quella indirizzata a questo processo è la più robusta, efficiente e ben strutturata.
Di conseguenza è comprensibile che le skill necessarie per effettuare una buona messa in produzione (anche semplicemente decente in realtà) non riguardano esclusivamente la sfera della programmazione, ma effettuata a certi livelli sono necessari devops engineers e sysadmins che si occupino della “comunicazione” tra software e hardware.
Per fortuna però, ci vengono in soccorso soluzioni come Heroku (e in ambito molto più ampio Amazon AWS) che ci sollevano dall’esoso incarico di effettuare il vero e proprio deploy su una macchina online, fornendoci un’interfaccia decisamente più semplice da gestire.
Heroku
Parliamo ora della mia piattaforma attuale di scelta: Heroku.
Ci sono molte soluzioni in giro, dalle più diverse, a quelle più simili ad Heroku e ognuna può essere più conveniente rispetto ad un’altra (in base alle proprie esigenze e ai parametri di scelta).
Heroku è generalmente considerato:
- Molto costoso.
- Molto efficiente e semplice da utilizzare, grazie a un fantastico cli e della documentazione ben strutturata.
In realtà, per quanto riguarda il primo punto, vi farò ricredere; molte persone non conoscono bene questa piattaforma e alla sola vista della pagina dei prezzi, i developer vengono percorsi da brividi lungo la schiena.
I linguaggi di sviluppo disponibili su Heroku sono: Node.js, Ruby, Java, PHP, Python, Go, Scala e Clojure. Noi vedremo come fare il deploy di applicazioni Node.js prendendo il mio precedente tutorial sulla creazione di un bot per facebook.
Cos’è un Dyno?
Un po’ come nell’algoritmica, dove abbiamo strumenti tra i quali il famoso “O grande” per misurare gli algoritmi, anche Heroku necessita in qualche modo di conoscere e misurare il consumo che le nostre applicazioni effettuano delle loro risorse. Lo fanno attraverso i “dyno“.
In sostanza un dyno è un container Linux che Heroku ci mette a disposizione per far girare la nostra applicazione.
Tipi di dyno
Esistono diversi tipi di dyno, ecco una tabella comparativa di quelli attualmente disponibili:
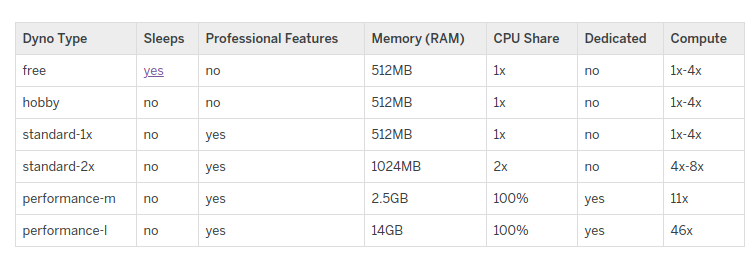
Noi ci focalizzeremo sui free che paradossalmente sono quelli più intricati da comprendere in quanto, essendo gratuiti, piuttosto che farsi pagare, scalano il tempo di attività del dyno da un totale di ore fornite mensilmente alla registrazione dell’account (tutti gli altri tipi, quindi hobby, standard-1x ecc. essendo a pagamento, una volta attivi non consumano tempo totale da queste ore disponibili fornite).
Le ore che abbiamo a disposizione mensilmente alla registrazione dell’account sono 450, alla semplice aggiunta di una carta prepagata, queste salgono a 1000 (quindi +550). Se vi fate il conto, in un mese ci sono 768 ore. Ciò significa che possiamo tenere gratuitamente un’applicazione su heroku che lavora 24h/7g.
Questo però in una visione semplicistica delle cose.
Perché se abbiamo compreso che un dyno non è nient’altro che un container, possiamo facilmente immaginare come un’applicazione possa utilizzare più di un semplice dyno. Immaginateli come dei processi, non tutte le applicazioni quindi girano con un singolo processo.
Possiamo però dire, in linea generale, che per applicazioni semplici, riusciamo tranquillamente a far girare la nostra applicazione con un singolo dyno (bot di telegram, web app in stile trello ecc.)
Configurazione dei dyno
I dyno esistono in tre configurazioni:
- Web: gli unici dyno che ricevono traffico dalla porta 80 (http) e 443 (https) sono quelli “web”. Dispongono della particolarità per cui se non ricevono traffico per 30 minuti consecutivi, questi vanno in stand-by finché non ricevono di nuovo traffico per riattivarsi quasi istantaneamente. È una funzionalità comoda in quanto ci permettono di risparmiare le ore totali disponibili e non dobbiamo occuparci di nulla a livello di codice.
- Worker: questi dyno non entrano mai in stand-by ma non possono in nessun modo ricevere traffico HTTP. Sono molto utili per smistare jobs in background, effettuare task o, se implementati attraverso polling, mettere in piedi dei bot (purtroppo se avete letto il mio articolo linkato precedente sui bot, sapete che solo Telegram permette di utilizzare il polling. Sfruttare le webhook invece, significa ricevere richieste da parte della piattaforma in questione sulla porta 80).
- One-off: Sono dyno particolari e temporanei, utilizzati per task come migrazioni di db e poco altro.
Quali e quanti dyno la nostra app utilizza, è specificato in un determinato file del nostro progetto specifico di Heroku che andremo a creare. Scopriamo come nel prossimo paragrafo.
prepariamo la nostra app
In questo paragrafo cerchiamo di capire come effettivamente “caricare” la nostra app su Heroku. Per ogni tipo di problema o curiosità, oltre a poter fare riferimento direttamente alla documentazione ufficiale, potete dare un’occhiata alla guida step-by-step di Heroku appositamente creata per node.js (che trovate qui).
Abbiamo chiaramente bisogno di un account registrato e piuttosto che effettuare il login via web, scarichiamo il tool ufficiale per la nostra piattaforma ed effettuiamo il login digitando nel terminale: heroku login
Una volta inserite username e password, possiamo passare all’effettiva creazione di una nostra applicazione (come già detto all’inizio, utilizzerò il bot di facebook creato in un tutorial precedente che trovate a questa repo, ma dovreste riuscire facilmente ad applicare quanto segue a qualunque altra app scritta in node).
Rechiamoci quindi nella cartella del nostro progetto e creiamo un’applicazione sul nostro account di Heroku dando questi comandi:
$ cd nodejs-facebook-bot $ heroku create Creating app... done, ⬢ sleepy-lake-76230 https://sleepy-lake-76230.herokuapp.com/ | https://git.heroku.com/sleepy-lake-76230.git
Il comando “create” crea al volo un’applicazione nel nostro account di Heroku utilizzando una configurazione base e generando un nome casuale, restituendoci in risultato una repo git che potremo utilizzare per effettuare il deploy e che heroku ha aggiunto tra i remote della repo locale per noi. Proviamo infatti a dare: git remote -v
heroku https://git.heroku.com/sleepy-lake-76230.git (fetch) heroku https://git.heroku.com/sleepy-lake-76230.git (push) origin https://github.com/giacomocerquone/nodejs-facebook-bot.git (fetch) origin https://github.com/giacomocerquone/nodejs-facebook-bot.git (push)
Se poi vogliamo rinominare la nostra applicazione, basta andare sul pannello di amministrazione (via web), selezionare l’app ed entrare nella scheda “settings”.
Via web, come avrete notato, possiamo fare un’infinità di cose, tra le quali aggiungere variabili d’ambiente e aggiungere degli add-ons (esclusivamente se si è aggiunta una carta prepagata) come un istanza di MongoDB attraverso MongoLab o per far girare la nostra applicazione su HTTPS.
Quindi tutto ciò a cui il deploy si riduce, grazie ad Heroku, è un push su una repo. Prima di farlo però, vediamo come configurare questi dyno.
Procfile
Abbiamo bisogno di creare un file chiamato: Procfile nella root del progetto, il quale sarà strutturato in questo modo:
dyno-configuration: comando-da-eseguire
Potendo considerare semplicisticamente un dyno come un processo, come già detto, ogni dyno avrà associato un determinato comando da eseguire. Nel caso del nostro bot, abbiamo bisogno di un dyno “web” in quanto ha bisogno di controllare il traffico in entrata sulla porta 80 (che sarà smistato per noi dallo stack di routing di Heroku) e il comando da eseguire sarà lo stesso che utilizziamo per eseguire l’app in locale. Quindi il nostro Procfile sarà cosi definito:
web: node index.js
Se avessimo utilizzato un dyno di tipo “worker” non era necessario scrivere: worker: node index.jsin quanto qualunque dyno che non sia definito esplicitamente come “web” viene considerato un worker.
Tips: Heroku, per app scritte in node.js, non necessita neppure di un Procfile ben definito fintanto che ci sia almeno uno script di start nel package.json. Rimane comunque importante inserirlo per una questione di uniformità agli altri linguaggi e agli standard vigenti in quanto anche altri sistemi di deploy utilizzano Procfile.
Env var
Una parte fondamentale di ogni applicazione che si rispetti sono le variabili di ambiente. Nell’esempio del nostro bot, i dati tipici che finirebbero nel nostro sistema come variabili d’ambiente sono le Chiavi API forniteci da Facebook. Possiamo gestirle sia da web che da cli molto semplicemente attraverso questi comandi:
heroku config:set MY_ENV_VAR=1 // Settiamo la variabile d'ambiente MY_ENV_VAR a 2 nel dyno di heroku heroku config // Per visualizzare le variabili d'ambiente settate nel dyno dy heroku
e vediamo come leggere le variabili d’ambiente da node.js (cosicché ogni stringa che contiene informazioni sensibili viene sostituita dalla seguente sintassi):
process.env.MY_ENV_VAR
E quando siamo in locale? Le aggiungiamo ogni volta a mano nel nostro sistema? Possiamo fare meglio di cosi.
Heroku mette a disposizione il comando: heroku local che avvia tutti i dyno elencati nel Procfile (attraverso i comandi lì definiti chiaramente) e carica le variabili di ambiente da un file nominato “.env”. È fondamentale che questo file non venga inserito in alcun commit, per questo aggiungetelo al vostro .gitignore.
Ultimi step
Finalmente ci siamo, non rimane nient’altro che assicurarci che il nostro package.json evidenzi tutte le dipendenze necessarie sotto il campo “dependencies” in modo che una volta effettuato il push del codice, Heroku può fare la build del progetto per noi. In effetti è possibile anche fornire una versione specifica dell’engine di node in casi di incompatibilità.
Diamo quindi: git push heroku master e in risposta abbiamo:
$ git push heroku master Counting objects: 12, done. Delta compression using up to 4 threads. Compressing objects: 100% (11/11), done. Writing objects: 100% (12/12), 5.87 KiB | 0 bytes/s, done. Total 12 (delta 2), reused 0 (delta 0) remote: Compressing source files... done. remote: Building source: remote: remote: -----> Node.js app detected remote: remote: -----> Creating runtime environment remote: remote: NPM_CONFIG_LOGLEVEL=error remote: NPM_CONFIG_PRODUCTION=true remote: NODE_VERBOSE=false remote: NODE_ENV=production remote: NODE_MODULES_CACHE=true remote: remote: -----> Installing binaries remote: engines.node (package.json): unspecified remote: engines.npm (package.json): unspecified (use default) remote: remote: Resolving node version 8.x... remote: Downloading and installing node 8.9.4... remote: Using default npm version: 5.6.0 remote: remote: -----> Restoring cache remote: Skipping cache restore (not-found) remote: remote: -----> Building dependencies remote: Installing node modules (package.json + package-lock) remote: added 53 packages in 1.613s remote: remote: -----> Caching build remote: Clearing previous node cache remote: Saving 2 cacheDirectories (default): remote: - node_modules remote: - bower_components (nothing to cache) remote: remote: -----> Build succeeded! remote: ! This app may not specify any way to start a node process remote: https://devcenter.heroku.com/articles/nodejs-support#default-web-process-type remote: remote: -----> Discovering process types remote: Procfile declares types -> (none) remote: Default types for buildpack -> web remote: remote: -----> Compressing... remote: Done: 18.4M remote: -----> Launching... remote: Released v3 remote: https://sleepy-lake-76230.herokuapp.com/ deployed to Heroku remote: remote: Verifying deploy... done. To https://git.heroku.com/sleepy-lake-76230.git * [new branch] master -> master
Dalla risposta possiamo vedere come ci vengono ritornate diverse informazioni, tra cui l’avviso di “Build succeded”.
Conclusione e tips
Prima di concludere ritengo necessario listare di seguito alcuni comandi utili:
heroku open // Apre l'url associato alla nostra applicazione heroku ps // Verifica il consumo dell'app corrente e il totale di ore disponibili rimanenti heroku logs // Legge i log tirati fuori dall'applicazione dopo il suo avvio heroku apps:delete // Eliminate l'app della directory corrente dal pannello di heroku
Questo è “tutto” o almeno lo è come avvio. Se volessimo davvero pubblicare un’applicazione importante e di grandi dimensioni su un sistema del genere, bisognerebbe interfacciarsi programmaticamente con Heroku per avviare diversi dyno per gestire il traffico e bilanciarlo, altri per aggiornare i database e altri ancora per eseguire chissà quale altra funzione… insomma, come tutte le cose, anche questa può divenire una cosa molto complessa.
Buon divertimento 😉